


Claude Codeに記事を読ませようとしたら、よく『取得できませんでした』って言われるんだけど…
Claude Codeにウェブページを読ませたり、キーワードでリサーチさせたりすると、意外とこの空振りに出くわしますよね。
Claude Codeのリサーチ方法がいくつかあって、使い方によって「取れる/取れない」はもちろん、集まる情報の量も正確さも大きく変わります。
そこでこの記事では、いくつものリサーチ方法を実際にひとつずつ検証して、たどり着いた「目的別のベスト」を、データと画像付きで紹介します。
リサーチの方法に種類なんてあるの?
あるんですよ♪まずはどんな種類があるのか、ざっくり整理するところから始めましょう。

ClaudeCodeのウェブリサーチ方法は大きく3種類

リサーチのやり方はいろいろありますが、ざっくり言うと取得の仕組みで3タイプに分けられます。まずはそれぞれの特徴を解説します。
ClaudeCode標準のWebFetch
Claude Codeに最初から付いている、いちばん基本の取得方法です。「このページを見て」とURLを渡すと、そのページの中身をまるごと持ってきてくれます。
ただ、ひとつクセがあります。ページが完全に表示され終わるのを待たずに中身を取りにいくので、食べログやSUUMOのように「開いたあとから中身が次々と出てくるサイト」だと、まだ何も入っていない状態のページを持って帰ってしまうことがあるんです。
ためしに、WebFetchで法律サイト(e-Gov)の中の情報をリサーチさせたところ、受け取ったデータはたった799バイトで、中身は空っぽでした。
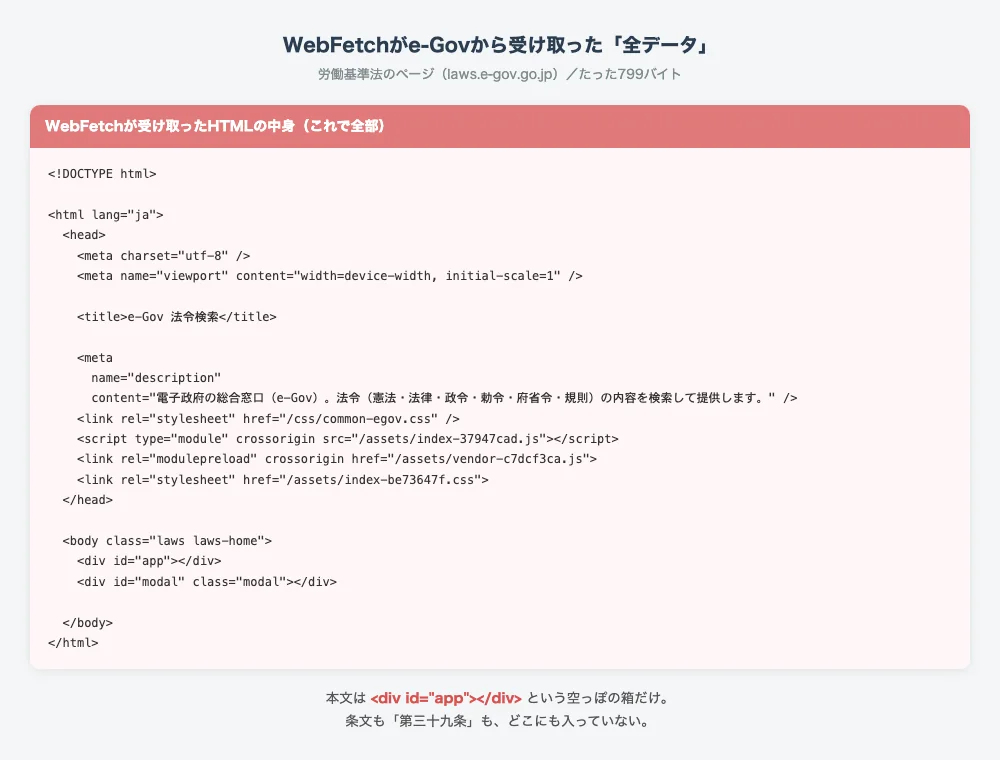
だったら表示し終わるまで待てばいいのに…
それが、待っても解決しないんですよ。
WebFetchは届いた文章を読むだけで、ページを動かして表示を完成させる機能を持っていないんです。郵便で届いた書類を読むようなもので、書類が白紙でも手元ではどうにもできない。
だから「中身が後から表示されるサイト」だと、WebFetchはこの空っぽの状態を受け取って終わってしまうわけです。
このWebFetchの弱点をカバーできるのが、次に紹介するツールたちです。
URLをMarkdownに変換するリーダー型
次が「リーダー型」、代表がJina(ジーナ)です。同じくURLを渡すのですが、WebFetchが「中身まるごと」なのに対して、Jinaは本文だけをスッキリ抜き出して渡してくれます。
広告やメニュー、デザインの飾りを削ぎ落として、読みたい中身だけを残して渡してくれるイメージです。
実際どれくらい違うのか、同じページで受け取った内容を見比べてみましょう。

左がWebFetchで右がJinaの変換後です。Jinaのほうがタイトルと本文だけがきれいに並んでいて、人が読む場合でもわかりやすいですよね。
AIに読ませるときも、右のJinaのほうがムダがなくて速いというわけです。
検索から取得まで完結する検索一体型
3つ目が「検索一体型」、代表がTavily(タヴィリー)です。
これは名前のとおり、検索と記事内容の取得が一体になっているのが特徴です。たとえば「相続税について調べて」とClaudeCodeにお願いする際に、WebFetchとTavilyでは下記のように手順が異なります。
【WebFetchでリサーチする場合】
- webSearchなどの検索機能で記事のURLを探す
- そのURLをWebFetchに1つずつ渡してページの中身を読む
- 記事の数だけ2を繰り返す
WebFetchは「渡されたURLを開いて読む」だけなので、URLを探す工程は別途必要で、しかも1ページずつしか読めません。
【Tavilyでリサーチする場合】
- Tavilyにキーワードを渡す
- 検索からURL選び、複数記事の取得まで、Tavilyが一度にまとめて返す
Tavilyは「キーワードを渡せば複数記事が一気に返る」。この工程の差が、後の検証で速さと取りこぼしの違いになって出てきます。
3種類あるのは分かったけど、結局どれを使えばいいの?
JinaとTavilyがおすすめかな
ClaudeCodeのリサーチはTavilyとJinaがおすすめ
検証結果から先に結論を言うとClaudeCodeでリサーチをするなら検索一体型の「Tavily」と、URLをマークダウンに変換する「Jina」というツールを使い分けるのがベストです。
ClaudeCodeが標準で使うWebFetchでは取得の失敗もしやすいことから、検索上位を目指す「SEO記事作成」を目的としたリサーチとしては、正直「う〜〜〜〜〜ん」という感じです。
普通のリサーチはTavilyが爆速で快適
「あるテーマについて広く情報を集めたい」「キーワードを入れてざっと調べたい」こういう一般的なリサーチなら、Tavilyがめちゃくちゃ便利です。
キーワードを1回投げるだけで、指定した件数の記事をまとめて取ってきてくれます。今回は10記事に設定して、実際に「相続税 基礎控除」で試してみました。同じキーワードでTavily・Jina・WebFetchを走らせた結果がこちらです。
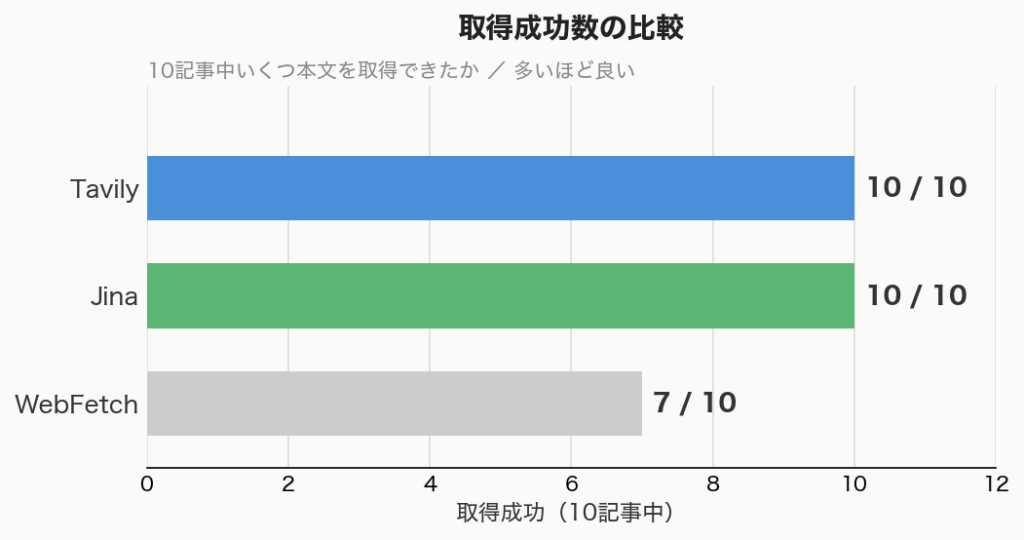
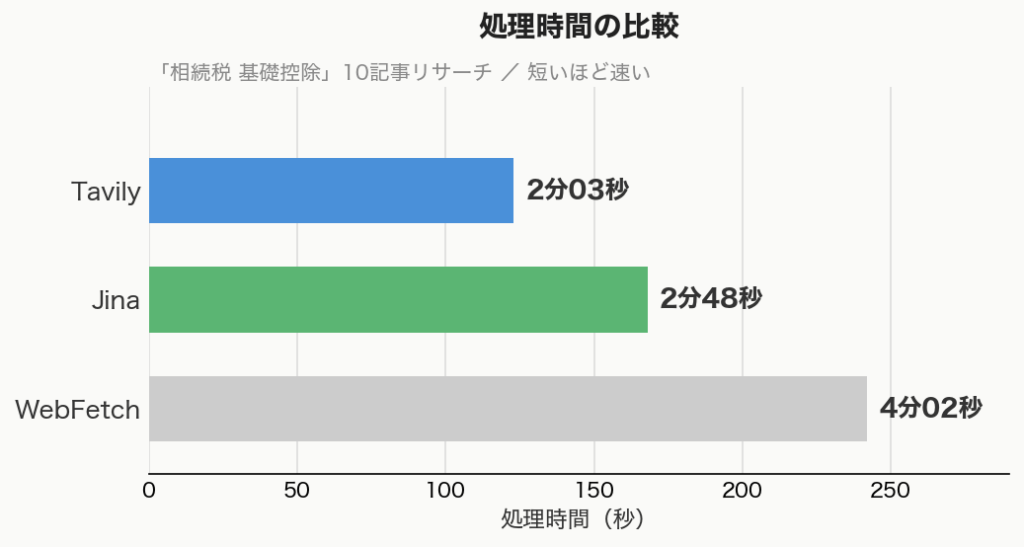
Tavilyは10記事すべてを2分03秒で取得、一方で標準のWebFetchは4分以上かかった上に3記事を取りこぼしました。正直、これまで普通のフェッチで1件ずつリサーチしていたのは何だったんだ…というレベルでした。
SEO競合分析はラッコキーワードとJinaの合わせ技
Google上位の競合記事を分析したいなら、ラッコキーワードでURLを集めてJinaで読むのがいちばん漏れがありません。
理由は2つあります。
1つめはTavilyの場合、取得してきたURL(記事)がGoogleの検索順位と大きく異なるからです。Tavilyが取得してきた記事と、実際の検索上位10記事を見比べてみると、同じ記事はたったの3つしかありませんでした。(後の検証でくわしく取り上げます)
これが「狙っているキーワードの競合リサーチ」には不向きという事実です。
2つめの理由が「WebFetchは正確なURLを渡しても取りこぼす」ためです。
実際に「相続税 基礎控除」の上位10記事で、標準のWebFetchとJinaを比べたら、こんな差が出ました。
| WebFetch(標準) | Jina | |
|---|---|---|
| 取得できた記事 | 7/10記事 | 10/10記事 |
| 拾えた見出しの数 | 111個 | 204個 |
WebFetchは政府広報・オリックス銀行・りそな銀行の3記事をエラーで取りこぼしましたが、Jinaは10記事すべて読めました。動的なサイトにも強いので、競合記事の中身を漏れなく拾えます。
このことから、SEOにおける競合分析においては「ラッコキーワードで検索上位記事の正確なURLを集めてJinaで確実に読む」という方法がベストだと思います。
ちなみに検索結果の記事URLを取得する方法は、ラッコキーワード以外にもあります。
個人的にはラッコキーワードが優秀すぎると思っているので、ラッコキーワード前提としています。
ということで、おさらいです。
ClaudeCodeで「◯◯についてちょっと調べてみてほしい〜」とかざっくりとしたリサーチが目的なら「Tavily」が爆速だし確実に取得できる情報が多いし消費トークンも抑えられるからおすすめです。ただ無料枠でできる回数や簡単な設定は必要です。
一方で「ブログを書く前提として、検索上位の記事構成や内容をリサーチさせたい」といった場合にはラッコキーワードなどで検索上位の記事URLや見出しを抽出し、Jinaで実際にその記事ページをリサーチさせる。というやり方のほうが合っています。
それぞれの使い方については、後半の「Jinaの導入方法」「Tavilyの導入方法」の目次で解説しているので、そちらをご覧ください。
ここから先は「実際こんな風に検証してみましたよ」っていうお話なので「とりあえず使ってみたいんだぜ」って人は導入方法のところまで読み飛ばしちゃってくださいね♪
WebFetchとJinaの比較検証
SEO競合分析で「競合記事の中身を正確に読めるか」を確かめるため、標準のWebFetchとリーダー型のJinaを実際に比較しました。条件はまったく同じURLに、まったく同じ質問を投げるだけ。
取得方法だけを変えて、情報の正確さと取得データ量(=コスト)にどんな差が出るかを見ます。
Google One料金ページで比較
検証に使ったのは、Google Oneの料金をまとめたこちらのページです。
> 対象ページ:Google Oneとは?料金や登録手順、メリット・デメリットを徹底解説(Sienca)
料金表が並んだシンプルな記事で試しました。結果、料金プランの数字はWebFetchもJinaもほぼ完璧に取得できて、精度はほぼ互角。
差が出たのはデータ量です。
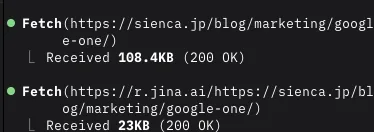
WebFetchが108.4KBだったのに対し、Jinaはなんと23KB。Jinaは生HTMLの約5分の1のデータ量で同じ情報を取得できたんです。余計な部分を削っているぶん、軽くて効率がいいんですね。
インボイスコラムで比較
次は数字がぎっしり詰まった税理士さんのコラムで検証。控除割合や計算例など、取りこぼすと一目で分かるテーマを選びました。
> 対象ページ:インボイス制度の経過措置とは?(小谷野税理士法人)
主要な数字はどちらも正確。ただ、ここで面白い差が出ました。「課税仕入れが1億円を超える部分は対象外」という細かい補足ルールを、生HTMLのWebFetchは拾って、Jinaは落としたんです。
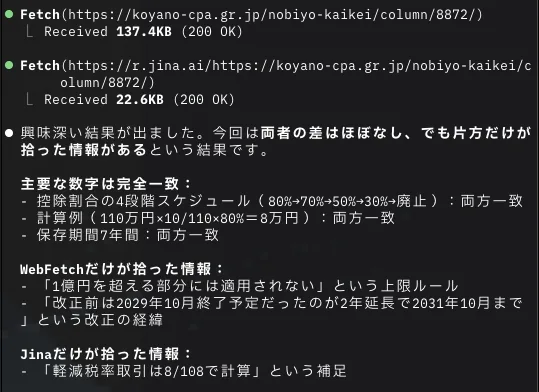
データ量はやっぱりJinaが軽くて、137.4KBに対して22.6KBの約6分の1。ただ、この検証で分かったのは「Jinaは常に高精度とは限らない」ということ。Markdownに変換する過程で、細かい補足が削られることもあるんですね。
じゃあWebFetchのほうが優秀なの?
それが、次の検証でひっくり返るんですよ笑
e-Gov労働基準法(動的SPA)で比較
3つ目は、あえて官公庁の法律サイト(e-Gov法令検索)を選びました。前の2つは最初から中身が全部入っているページでしたが、今度はページを開いた後から中身が読み込まれるタイプのサイトです。
> 対象ページ:労働基準法(e-Gov法令検索)
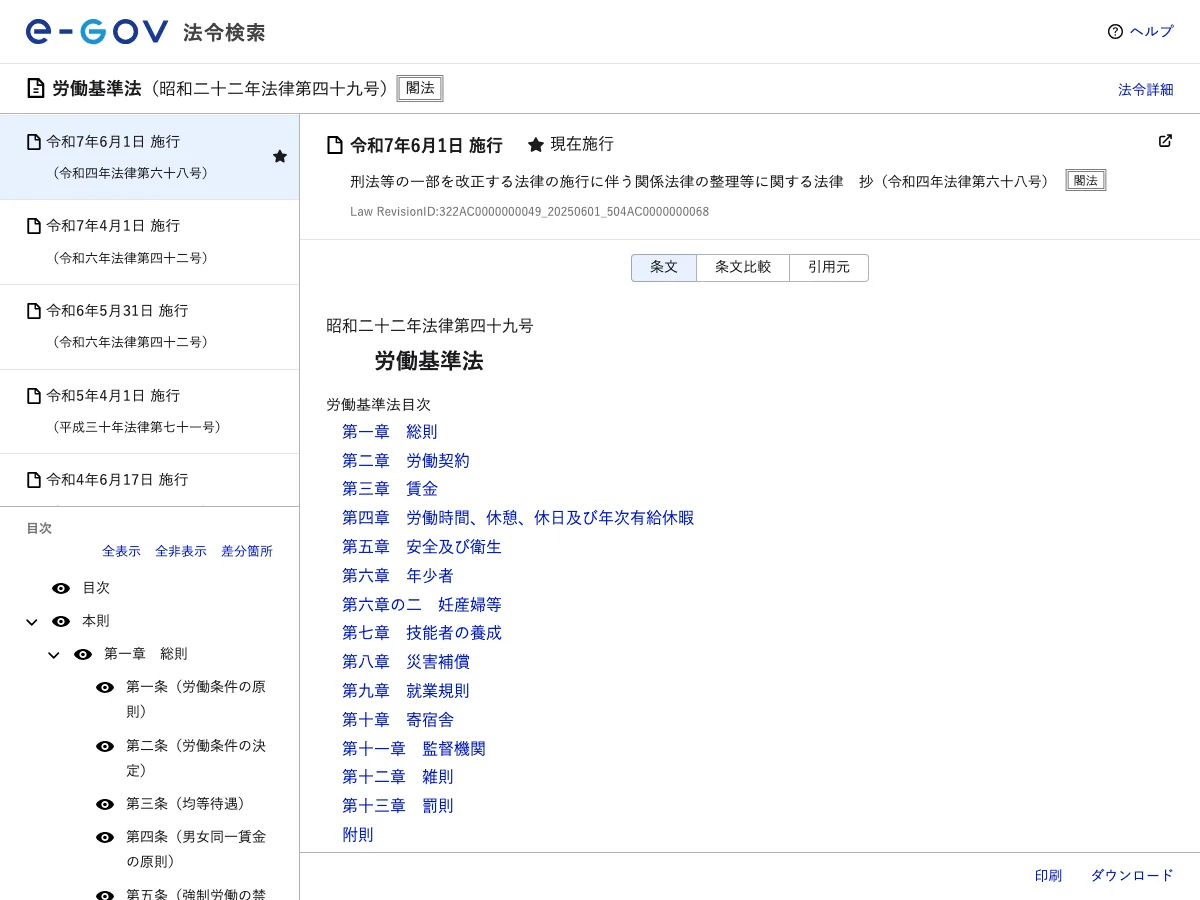
結果は、Jinaの圧勝。というより、WebFetchは取得そのものに失敗しました。
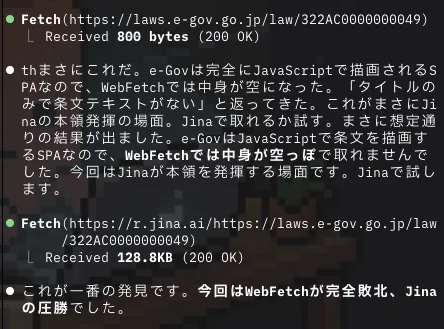
WebFetchが持ってきたのはたった800バイト。中身は空っぽで、肝心の条文が一文字も入っていませんでした。一方Jinaは128.8KBで、条文がフルテキストで取れています。
なぜこうなるかというと、WebFetchはページが「届いた瞬間の状態」しか受け取れないからです。e-Govは最初に届く状態が空のままで、そこから少し遅れて条文が表示される作りになっています。
WebFetchは条文が表示される前の段階のページを受け取ってしまうので、中身がない状態で取得が終わってしまいます。
Jinaはページが完全に表示されるまで待ってから中身を取ります。だから条文も含めてまるごと取得できたわけです。
「相続税 基礎控除」上位10記事で一括比較
最後は、いちばん実戦に近い検証です。「相続税 基礎控除」というキーワードのGoogle上位10記事を、まるごと読んで競合分析する。ブログの記事構成を作るときに、実際にやるリサーチですね。
Google上位10記事のURLはラッコキーワードで取得し、そのURLをWebFetch版とJina版それぞれに渡して、同じ条件で処理させました。
なんでわざわざラッコキーワードでURLを取得するの?ClaudeCodeに「◯◯のキーワードの検索上位10記事をリサーチして」って言えばよくない?
Claude Codeの検索は取得できるURLの件数も内容もバラつくので、Google上位10記事をきっちり揃えられないんですよ。
同じ「相続税 基礎控除」でGoogle(ラッコKW)とClaude CodeのWebSearchを比べてみます。
| 順位 | Google実際の結果(ラッコKW) | Claude Code WebSearchの結果 |
|---|---|---|
| 1位 | りそな銀行 | 三井住友信託銀行 |
| 2位 | 財務省 | りそな銀行 |
| 3位 | 国税庁 | ソニー生命保険 |
| 4位 | 政府広報オンライン | 政府広報オンライン |
| 5位 | 三菱UFJ信託 | オリックス銀行 |
| 6位 | SBI証券 | チェスター |
| 7位 | オリックス銀行 | 国税庁 |
| 8位 | チェスター | — |
| 9位 | クレアス | — |
| 10位 | 日経新聞 | — |
WebSearchは7件止まりで、財務省・三菱UFJ・SBI・クレアス・日経などGoogle上位の主要サイトが丸ごと欠けています。代わりにGoogle圏外のソニー生命保険が入っていたりします。
ラッコキーワードで取得したURLはGoogleの検索結果と一致するので、正確に10件・正しい順位で揃えられるんです。
ということで、ラッコキーワードで取得した上位10記事分のURLに対して、WebFetchとJinaで見出しを抽出してもらいました。
| Jina版 | WebFetch版 | |
|---|---|---|
| 取得成功 | 10 / 10 | 7 / 10 |
| 抽出した見出し総数 | 204個 | 111個 |
| 処理時間 | 2分48秒 | 4分02秒 |
WebFetchは10記事中3記事を取りこぼしました。しかも政府広報オンラインが「403エラー」、オリックス銀行が「404エラー」、りそな銀行が「タイムアウト」と、検索上位の主要なサイトばかり。
競合分析としては、これはちょっと痛いですね
処理時間もWebFetchはタイムアウトのリトライで時間を食ってしまっています。取れない上に遅いという二重の不利ですね。
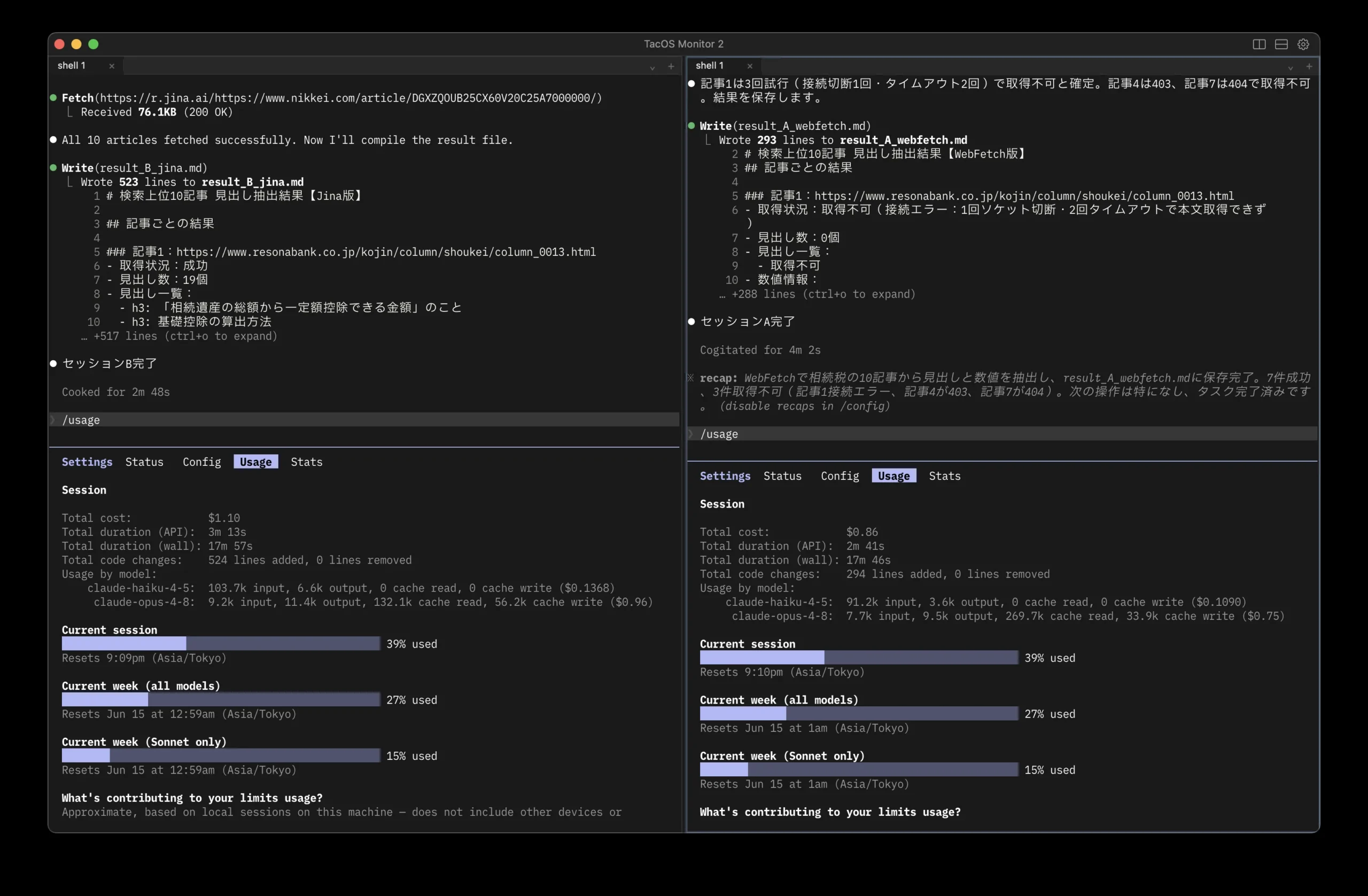
一方でコストの総額だけ見るとJina版が$1.10、WebFetch版が$0.86で、Jinaのほうが高くかかりました。
でもこれ、Jinaが10記事ぜんぶ中身を取ってきて、そのぶん多く処理したからなんですよね。
取れた記事1本あたりのコストで計算すると、Jinaのほうが安くなります。網羅性・速さ・1記事あたりの単価、どれを取ってもJinaが上でした。
Tavilyの検証
ここまではURLを自分で用意する方式でした。次は、キーワードを投げるだけの検索一体型Tavilyを、同じ「相続税 基礎控除」で検証してみます。
「相続税 基礎控除」で10記事一括取得
結果から言うと、これがもう…爆速でした。
| WebFetch | Jina | Tavily | |
|---|---|---|---|
| 取得成功 | 7/10 | 10/10 | 10/10 |
| 見出し総数 | 111個 | 204個 | 258個 |
| 処理時間 | 4分02秒 | 2分48秒 | 2分03秒 |
| コスト | $0.86 | $1.10 | $0.79 |
| URL選定 | 手動 | 手動 | 自動 |
3ツールの中でいちばん速い2分03秒。しかもJinaやWebFetchではURLを自分で用意する必要があったのに、TavilyはURL選定まで自動でやってくれます。キーワードを投げるだけで完結する手軽さは、やっぱり圧倒的でした。
え、じゃあもうTavilyだけでよくない…?
それがね、SEOの競合分析にはちょっと向いてないんですよ。
SEO競合分析には不向きな理由
これだけ優秀なTavilyですが、SEO目的のリサーチには注意点があります。それは、TavilyのURLがGoogle検索の順位と一致しないことです。
ここまで差がでてしまうのは、TavilyがGoogleの検索順位をそのまま並べているわけではないからです。
Tavilyは、検索した各サイトに独自の「関連度スコア」という点数を自動でつけ、その点数が高い順に返してきます。実際、APIの返り値を見ると、1サイトごとに score(0〜1の数値)がしっかり入っています。
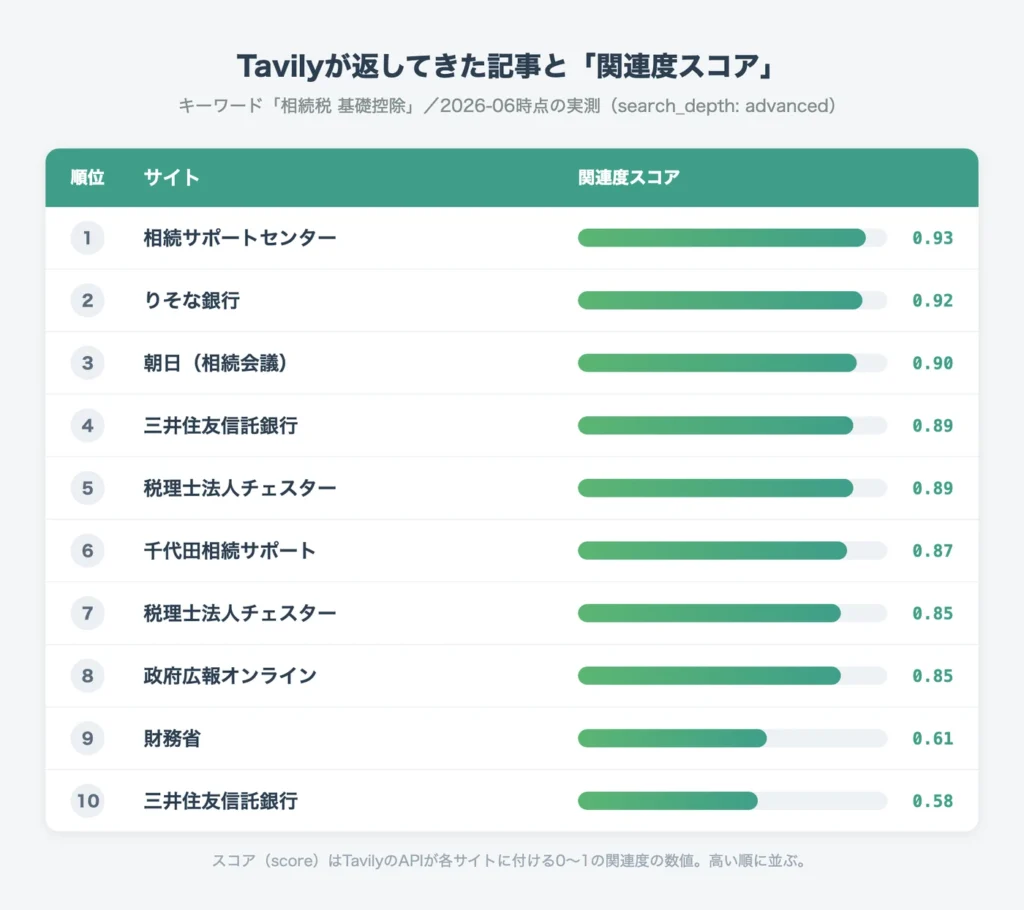
Googleが「世の中での評価・人気の順」で並べているのに対して、Tavilyは「この質問にどれだけ関連していそうかを、自分で採点した順」で並べているということです。
Googleの検索順位にこだわらない一般的なリサーチならTavilyが優秀ですね
取得の難しいサイトで比較
最後はちょっと意地悪な検証をしてみました。知恵袋・食べログ・Notion・SUUMOという、いずれも普通のツールでは中身を取りにくい4サイトで、Jina・Chrome headless・Tavilyを比べてみました。
Chrome headlessとは、画面を表示しないブラウザのことです。人が見るのと同じようにページを最後まで組み立ててから中身を取れるので、動的サイトに強いのが特徴です。
動的サイトも取れるなら、全部Chrome headlessでやればよくない?
毎回ブラウザを丸ごと起動するので、遅くてコストが跳ね上がるんですよね
しかも「WebFetchで取れなかったら自動でheadlessに切り替える」という動きは基本的にしてくれません。CLAUDE.mdにその旨を書いておけば自動化も可能ですが、そもそも「CLAUDE.mdに指示を書いていても、その指示を守る可能性は70%程度です」ってClaude公式が言っちゃってます笑
Chrome headlessは便利な反面、使い勝手はちょっと悪いんですよね…。
というわけで、一般的に取得しにくい4サイトの中身を見に行ってもらった結果は下記のとおりです。
| サイト | Jina | Chrome headless | Tavily |
|---|---|---|---|
| 知恵袋 | ❌ | ❌ | ✅ 回答37件まで取得 |
| 食べログ | ❌ ブロック | △ ナビ中心 | ✅ 22,401文字 |
| Notion料金 | △ 価格なし | ✅ 価格も取得 | △ アクセス元によって価格表示がずれることあり |
| SUUMO | ✅ | ✅ | ✅ |
結果を見ると、得意分野がきれいに分かれました。
外部からの自動アクセスを制限している知恵袋や食べログは、Tavilyだけが突破できました。一方で、Notionの料金のように「JavaScriptで後から表示される数字」を確実に取りたいときは、Chrome headlessが頼りになります。
Tavilyに△を付けたのは、価格がポンド表示で取得されたことがあったからです。Tavilyはアメリカ拠点のサービスなので、地域で価格を出し分けるNotionでは影響が出た可能性があります。ただ毎回ではなく、取り直したらドル価格で取得できました。
もうひとつ。JinaはJavaScriptで後から表示される数字(Notionの料金など)を取りこぼすことがあります。「動的サイトに対応する」は正しいけど、完璧ではないという点は頭に置いておくといいです。
Jinaの導入方法
ここからは実際の使い方です。まずJinaから。これがもう、拍子抜けするくらいかんたんです。
URLの頭に https://r.jina.ai/ を付けるだけ。 アカウント登録もAPIキーも要りません。
たとえば「https://example.com」というサイトなら「 https://r.jina.ai/https://example.com」という形です。
Claude Codeに使わせたいなら、CLAUDE.mdに「WebFetchするときは r.jina.ai/ を前置する」と書いておくと省略できることが多いです。ただ毎回確実に守られるわけではないので、重要なリサーチでは「r.jina.ai/を使ってリサーチして」と指示するほうが確実です。
というか雑に「Jina使って◯◯についてリサーチして」って言っても多分問題なく使ってくれます。
ただ1点補足すると、アカウント登録無しで使う場合は若干制限があります。それは「1分間に20回分のURLまでしか読めない」ということです。
まあ正直、一般的なリサーチなら1分で20URL読むことはまずない…万が一あったとしてもエラーになるだけです。そうなったらClaudeCodeが「エラーになったので制限内でもう一度リサーチします」って感じで、関西弁で言うと「あんじょう(いい感じに)」やってくれます。
「それ以上のリサーチをする!一気に100サイト分ぐらいを大規模なリサーチしてほしいぜ!」っていう場合は、Jina公式サイトでAPIキーを発行すると1分あたり500回、かつ1,000万トークンまで無料で使えるようになります。
ちなみに僕自身はAPIキー取らないまま、普段のリサーチは困ること無く普通に使えています。
Tavilyの導入方法
次にTavilyの導入方法を解説します。こちらはアカウント登録が必要ですが、それでも数分で終わります。
ちなみにTavilyも無料枠として、毎月1,000クレジット利用できます。
まずTavilyの公式サイトでアカウントを作ります。Google・GitHubなどのアカウントでもサインアップできて、クレジットカードなどの入力は不要です。
登録すると下記のような管理画面が表示されます。
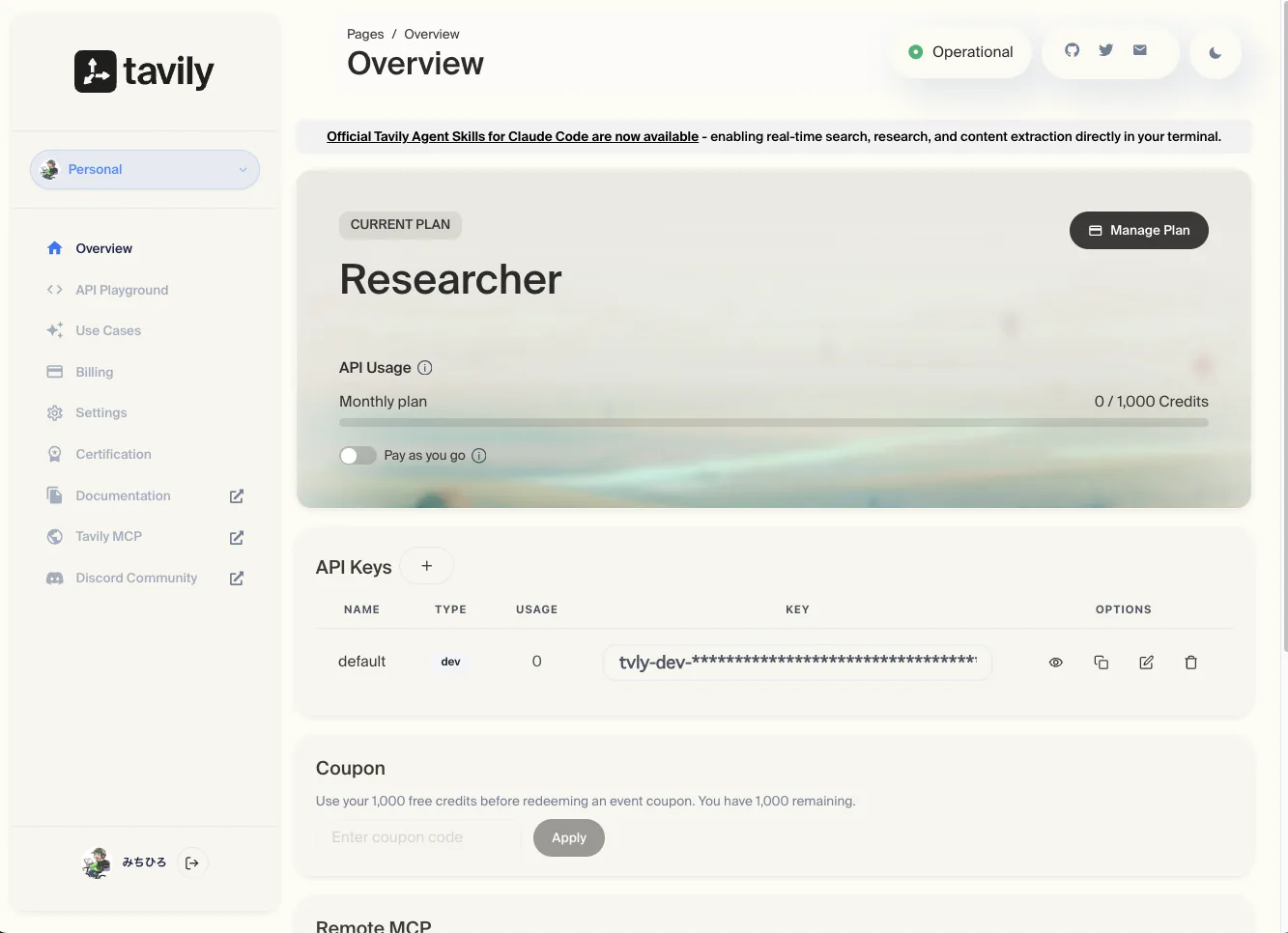
ここで月1,000クレジットの無料枠や、自分の使用量(0 / 1,000 Credits)が確認できます。
あとはClaude Codeにつなぐだけです。接続方法は2通りあって、コマンド1つで繋がるMCP接続と、スクリプトを自分で書くAPI利用があります。初心者の方はMCP接続がダンゼンラクです。
ターミナルを開いて(Macの場合はSpotlightで「ターミナル」と検索)、以下のコマンドを1回実行してください。
claude mcp add -s user tavily-remote-mcp --transport http https://mcp.tavily.com/mcp/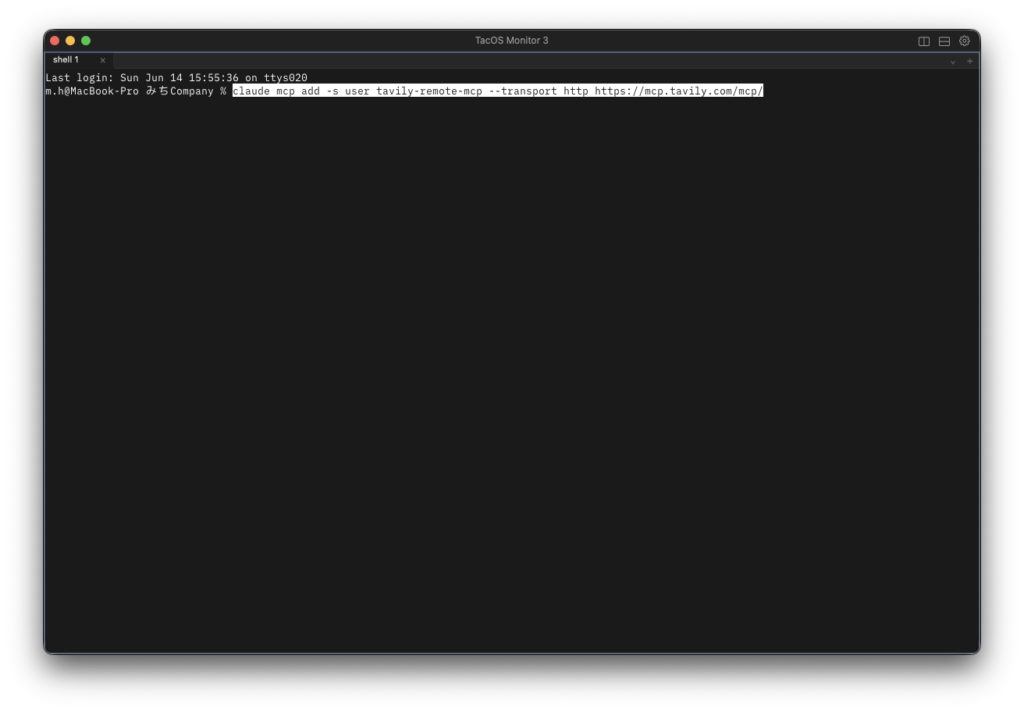
開いたブラウザでTavilyへのログインを許可すれば完了です。(このコマンドはTavily公式ドキュメントに記載のものです)
Tavilyのクレジット消費について
クレジットの消費量は検索が1〜2クレジット、5URLごとに1クレジットです。
例えば「『相続税 基礎控除』で10記事分リサーチして」って件数とキーワードを指定して使った場合の計算はこうなります。
- 検索1回 = 1クレジット
- 競合10記事の本文取得(10URL)= 2クレジット
- 合計 3クレジット/記事
ぜんぜん使わないね
ただし「◯◯についてリサーチして」ってキーワードだけで投げた場合、ClaudeCodeがよかれと思って様々な関連キーワードで複数回リサーチしようとします。その結果、クレジット消費は上記よりも増えるケースがあるのでちょっと注意ですね。
無料枠を使い切ったあとの課金については、少し安心できる仕組みになっています。それはクレジットカードを登録しない限り、従量課金(Pay as you go)もONにならないからです。
最初から従量課金はオフ設定になっています
Tavilyの管理画面でも、従量課金をする設定「Pay as you go」をONにしようとすると「Payment method required(支払い方法が必要です)」というダイアログが表示され、クレカなしでは進めない設計になっています。
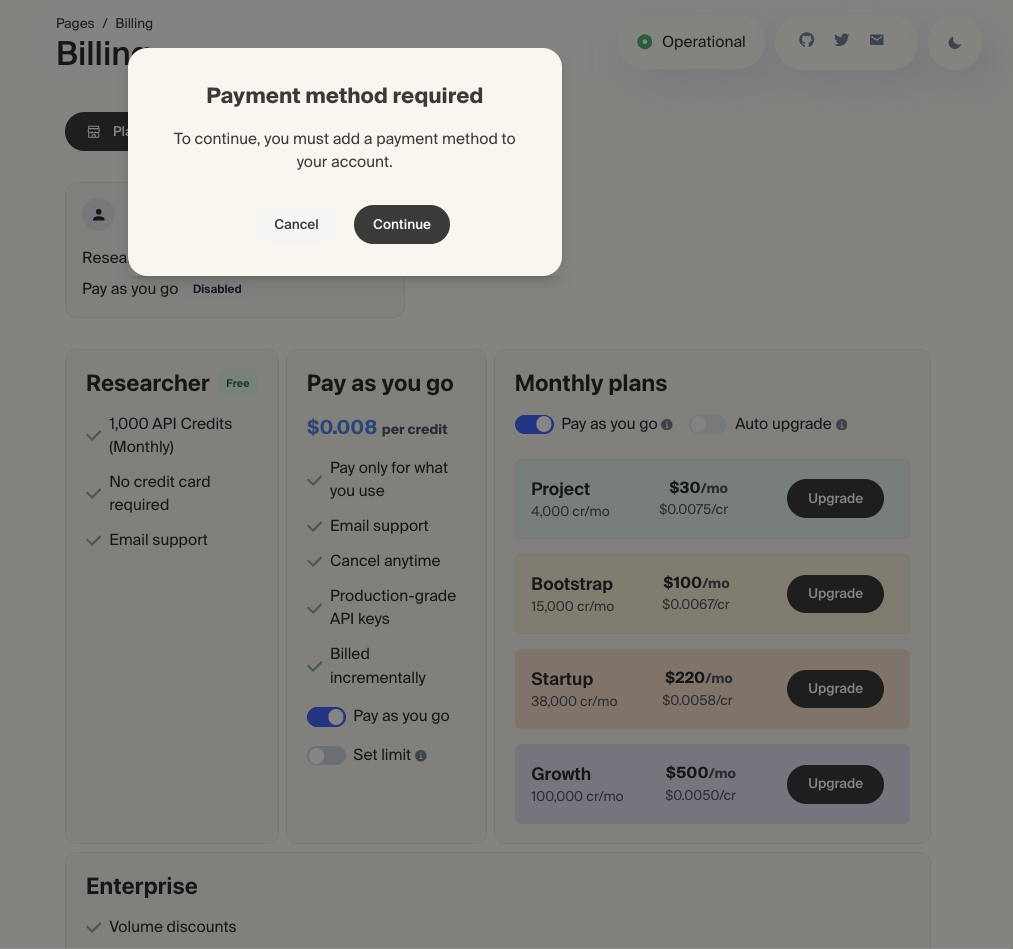
クレジットカードの登録さえしなければ「いつの間にかお金が発生していた!」なんてことにもなりません。
公式には「クレカなしでは1,000クレジット使い切ったあとは止まる」とは明記されていませんが、この仕様から判断すると「無料枠を使い切ったら、シンプルに使えなくなる(課金してくれ〜という通知が来る)」と思われます。
実際僕はクレジットカードの登録なしで、いまのところ無料枠だけで使っています。
クレカを登録してPay as you goをONにした場合でも、「Set limit」で上限金額の設定はできます。
まとめ:ツール選びでClaude Codeのリサーチ精度は変わる
最後に、今回の検証をまとめておきます。
- 標準のWebFetchだけだと動的サイトを取りこぼす(上位10記事で3割欠けた)
- ざっくり情報を集めるならTavilyが爆速で網羅的
- Google競合分析をするならラッコキーワード+Jinaが正確
同じ「リサーチ」でも、ツールを選ぶだけで集まる情報の量も正確さもこれだけ変わります。目的に合ったツールを選べば、欲しい情報を取りこぼさずに集められる。これが今回いちばん伝えたかったことです。
むずかしく考えなくて大丈夫。まずはJinaの「URLの頭に r.jina.ai/ を付けるだけ」から試してみてください。
たったこれだけで、Claude Codeのリサーチが見違えますよ♪